在當(dāng)今數(shù)字化時代,信息技術(shù)(IT)的快速發(fā)展使得高質(zhì)量的演示文稿(PPT)成為知識傳遞、項目匯報與行業(yè)交流的重要工具。無論是互聯(lián)網(wǎng)通信、計算機(jī)軟件工程,還是網(wǎng)絡(luò)與信息安全領(lǐng)域,一份結(jié)構(gòu)清晰、設(shè)計專業(yè)的PPT模板都能顯著提升演示效果。本文將圍繞用戶提供的“互聯(lián)網(wǎng)通信計算機(jī)軟件工程網(wǎng)絡(luò)安全ppt模板下載 8.97mb 信息技術(shù)ppt大全 行業(yè)介紹ppt 網(wǎng)絡(luò)與信息安全軟件開發(fā)”等關(guān)鍵詞,為您梳理相關(guān)資源與行業(yè)知識。
一、信息技術(shù)PPT模板資源概述
1. 資源類型與內(nèi)容
“信息技術(shù)PPT大全”通常涵蓋廣泛的子領(lǐng)域,包括但不限于:
- 互聯(lián)網(wǎng)通信:介紹5G/6G、物聯(lián)網(wǎng)(IoT)、云計算、邊緣計算等前沿通信技術(shù)與架構(gòu)。
- 計算機(jī)軟件工程:涉及軟件開發(fā)流程(如敏捷開發(fā)、DevOps)、編程語言、軟件測試與項目管理。
- 網(wǎng)絡(luò)與信息安全:聚焦網(wǎng)絡(luò)安全威脅、加密技術(shù)、防火墻、入侵檢測系統(tǒng)(IDS)、數(shù)據(jù)隱私保護(hù)及安全策略。
- 軟件開發(fā):包括前端/后端開發(fā)、移動應(yīng)用開發(fā)、人工智能與大數(shù)據(jù)應(yīng)用等。
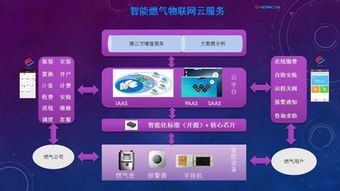
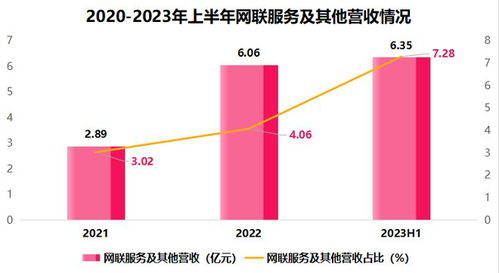
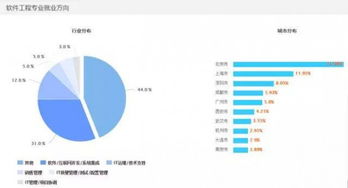
這些模板往往包含專業(yè)的圖表(如網(wǎng)絡(luò)拓?fù)鋱D、數(shù)據(jù)流程圖)、配色方案(多采用科技藍(lán)、深灰等色調(diào))以及模塊化布局,方便用戶快速填充內(nèi)容。
2. 模板下載與大小
用戶提到的“8.97MB”是一個典型的PPT文件大小,表明模板可能包含較多高質(zhì)量圖像或動畫效果。在下載時,建議通過正規(guī)渠道(如專業(yè)PPT平臺、教育機(jī)構(gòu)網(wǎng)站或開源資源庫)獲取,以確保文件安全且無病毒。注意檢查文件格式(如.pptx或.ppt)是否與您的辦公軟件兼容。
二、行業(yè)介紹PPT的核心要素
一份優(yōu)秀的“行業(yè)介紹PPT”應(yīng)具備以下結(jié)構(gòu):
- 封面頁:醒目標(biāo)題(如“網(wǎng)絡(luò)與信息安全開發(fā)現(xiàn)狀與趨勢”)、副標(biāo)題及演示者信息。
- 目錄:邏輯清晰的章節(jié)劃分,引導(dǎo)聽眾理解內(nèi)容脈絡(luò)。
- 行業(yè)背景:概述信息技術(shù)的發(fā)展歷程與當(dāng)前市場規(guī)模,強(qiáng)調(diào)互聯(lián)網(wǎng)通信和網(wǎng)絡(luò)安全的重要性。
- 技術(shù)詳解:分模塊介紹軟件工程方法論(如瀑布模型 vs. 敏捷開發(fā))、網(wǎng)絡(luò)安全技術(shù)(如零信任架構(gòu))等。
- 案例研究:通過實際案例(如某企業(yè)軟件開發(fā)項目或安全漏洞事件)說明理論與實踐的結(jié)合。
- 趨勢與挑戰(zhàn):分析人工智能、區(qū)塊鏈等新興技術(shù)對行業(yè)的影響,以及人才短缺、數(shù)據(jù)泄露等挑戰(zhàn)。
- 與展望:重申核心觀點,提出未來發(fā)展方向。
- 附錄與參考文獻(xiàn):提供數(shù)據(jù)來源或擴(kuò)展閱讀材料。
三、網(wǎng)絡(luò)與信息安全軟件開發(fā)的關(guān)鍵點
在“網(wǎng)絡(luò)與信息安全軟件開發(fā)”領(lǐng)域,PPT內(nèi)容需突出:
- 安全開發(fā)生命周期(SDLC):將安全措施集成到軟件開發(fā)的每個階段,從需求分析到部署維護(hù)。
- 常見安全漏洞:如SQL注入、跨站腳本(XSS)等,并演示如何通過代碼審計和滲透測試來防范。
- 工具與框架:介紹OWASP Top 10、安全編碼指南,以及使用如Burp Suite、Wireshark等工具進(jìn)行安全評估。
- 合規(guī)性要求:提及GDPR、網(wǎng)絡(luò)安全法等法規(guī)對軟件開發(fā)的影響。
四、實用建議與資源獲取
- 定制化修改:下載模板后,根據(jù)您的具體需求調(diào)整色彩、字體和內(nèi)容結(jié)構(gòu),以保持品牌一致性。
- 資源平臺:可訪問SlideModel、Slidesgo、OfficePLUS等網(wǎng)站搜索“信息技術(shù)”或“網(wǎng)絡(luò)安全”主題模板,部分提供免費選項。
- 文件優(yōu)化:若PPT文件過大(如超過10MB),可壓縮圖片或刪除冗余動畫來減小體積,便于分享與演示。
利用專業(yè)PPT模板不僅能提升演示效率,還能增強(qiáng)內(nèi)容的權(quán)威性與吸引力。在互聯(lián)網(wǎng)通信和網(wǎng)絡(luò)安全日益重要的今天,通過精心準(zhǔn)備的演示文稿,您可以更有效地傳達(dá)技術(shù)見解,推動行業(yè)交流與創(chuàng)新。